Organizations that have existed for many years have vast files containing formal and legal documents. Some examples include notarial acts as well as lease, rental, terms & conditions, and other similar types of agreements between enterprises or public entities.
With time, companies develop and acquire new customers causing their archives to grow even more. This is a cause of concern for many organizations in the telecommunications, energy, heating, and water & sewage utilities sectors. Depending on the case, they either maintain their documentation entirely on paper or only a part of it is digitized.

To ensure the efficacy of both emergency and routine business operations, data retrieval must be fast and easy. This is possible by maintaining a database with categorized and structured data that allows you to quickly access specific information or a particular data set. A digital database makes it much easier to analyze and interpret data as well as create reports. It is much better than a paper archive or a simple digital repository that uses optical character recognition to read scanned documents. Paper archives and simple digital repositories allow you to search for specific information, but their unstructured nature makes working with data slow and challenging.
This raises some questions: how to efficiently move data from paper documents to structured databases? Is there a way to improve this process?
How is data transferred from documents into a database?
Usually, the answer to this question is very easy and much less spectacular than we would expect it to be.
Data entry is performed by a person, often someone hired for this sole purpose. They copy key information from documents and enter it manually into appropriate database sections. The data usually includes agreement dates, numbers, and types, as well as case register numbers and land registration numbers. Data moved into a database can be used across many company departments (such as customer service), significantly improving work quality.

If there aren’t many documents and data entry doesn’t take too long, this process shouldn’t be extremely challenging, (although it is still tedious). On the other hand, especially large, established companies deal with an overwhelming number of documents and amounts of data that continue to grow and need to be entered into a database, so in their case, such work can take a full-time job. Therefore, a company needs to employ a person whose only task is to enter data from documents into a database.
Manual data entry causes many issues:
How to improve the data collection process for formal and legal paper documentation?
Globema is known for conducting research & development projects, which is why we have decided to investigate this problem to find a better way for companies to collect data contained in paper documents.
Our answer was using artificial intelligence and machine learning (AI/ML) algorithms and automating the process. We reached back to our experience with the LocDoc application where we used artificial intelligence to classify documents and read data from the technical as-built documentation.
We used similar AI/ML mechanisms as in the LocDoc solution but this time, we automated the process of reading and entering data contained in formal and legal documents into databases that are already being used in organizations. This is how iDoc came to be.
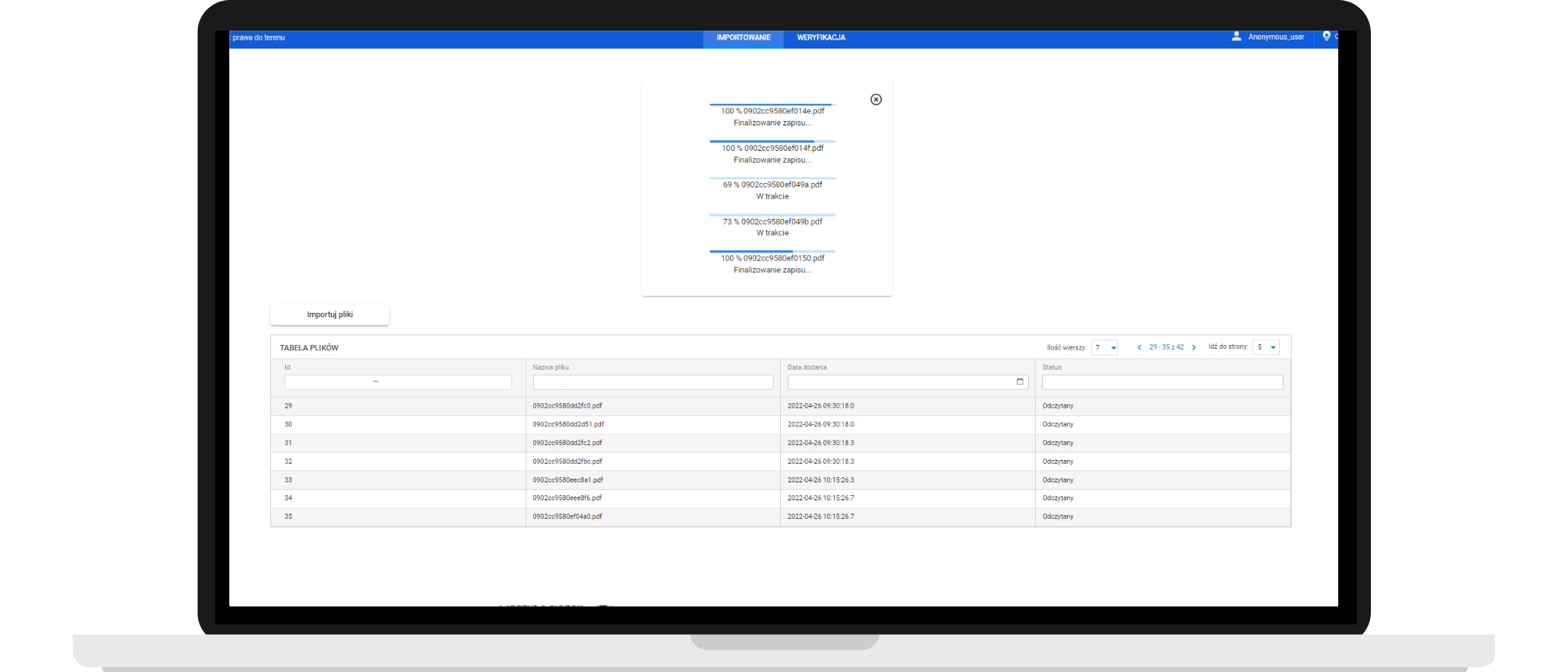
Click to zoom
iDoc application. Loading scanned documents into the system – preparation for data reading and categorization.
How does iDoc, a solution for automated data extraction and classification work?
The iDoc solution uses AI/ML algorithms to automatically read and classify data contained in formal and legal documents.
iDoc can understand and read formal and legal documents such as:
- notarial acts
- lease agreements
- rental agreements
…and other similar types of agreements between enterprises or public entities. Every type of agreement is different and contains unique information.
The algorithm reads the information contained in a document and recognizes its type (classifies it). Then, it collects the information and saves it in a database according to the attributes (document categories and data types). This database can be integrated with other databases or systems that operate at a company.
The range of data contained in agreements is very broad (usually about 30 to 40 different attributes and data categories, depending on the document type). For example:
- data about contracting parties (company names, owners, contractors, attorneys, notaries, etc.)
- address data (addresses of all contracting parties, plot numbers, etc.)
- contract duration
- contract dates
- agreement identification numbers such as the land registration number
- object details
- information about the contract subject
- payment data

Processing one notarial act (reading, classifying, and entering data into a database) takes iDoc a dozen or so seconds, which is a result unattainable for a human. On average, a person needs 11 minutes to process a 6-page document.
Stoen Operator
AI improved information retrieval about easements from paper documents
See how, by using AI to read data, Stoen Operator has reduced the time spent archiving easement agreements and notarial deeds by more than 60%.
Can artificial intelligence do all the work and replace humans?
Globema’s solution is based on AI algorithms that can read and interpret data contained in paper documents, however, humans are still needed to enter data into the system. First, a person must upload scanned documents to iDoc (the solution does not scan documents, it can only read and classify data from scans). Most importantly, a person must verify data accuracy paying particular attention to the fragments that may be hard to read by a computer. This includes handwriting, stamps, blurred scans, creased or torn paper, as well as confusing structures e.g. when attributes are specified using indirect information.
What does the verification process look like? Every document is presented on the screen with highlighted key phrases recognized by the AI. Next to it, there is a panel with fields filled in with this recognized data. All objects and attributes are arranged in a logical order and are assigned colors that match the colors used to highlight the corresponding text on the scanned page. This “color code” allows users to quickly verify accuracy visually by comparing data between the two windows (documents and side panel).
Lastly, if needed, a user enters corrections and then accepts the document they have just verified.
As you can see, the human factor isn’t fully eliminated from the process. A person still plays a vital role – perhaps an even more important one than before. Instead of performing repetitive, mechanical copying, the person can now focus on data verification and managing the entire process of database updating and data quality maintenance.

Click to zoom
iDoc. View of data verification panel. You can easily check the accuracy of the read information (located in the window on the left) and compare it with the source in the document preview (on the right). The application also gives you a choice of backup candidates for the value of a given attribute and highlights them on the preview.
.
Statistical comparison between humans and iDoc
On average, a human can classify (recognize what type of document they are dealing with) about 3100 pages during a single workday. In the same time, an artificial intelligence algorithm can classify more than 30 000 pages maintaining at least 96% accuracy.
The situation is similar when it comes to reading and entering particular information into a database. During one workday, a person can read and enter about 2000 attributes into a database whereas a machine can move about 10 times as much data (which is about 20 000 attributes!) maintaining about 85% accuracy.

What this means is that, although they significantly speed up the work, algorithms cannot ensure 100% accuracy of the data they recognize. AI might consider a small amount of information as less accurate and suggest a user verify it. Therefore, the accuracy of attribute identification is defined as the ratio between all accurately recognized attribute values (those that did not require user corrections) and the sum of all attributes filled out by algorithms.
What are the benefits of using AI/ML for document classification?
It is hard to overrate the benefits of automating the data classification process. Especially if moving data from documents to a system takes most of a full-time position at your company and the documentation keeps on growing.
Using AI/ML and automating the process of entering formal and legal data contained in paper documents into a digital database means:
- 5-10 times faster classification and processing of data contained in documents
- moving the burden of tedious work from a human to a machine and letting employees focus on supervising the entire process
- there is no need for hiring a person responsible only for populating the database, this in turn lowers recruitment costs and employee turnover
- document digitization can be performed outside of working hours and without any breaks
- higher data quality: the automated process is not prone to fatigue and distractions – the factors which cause humans to make errors when entering data
- more complete databases. There is a much higher chance to move all information, including historical data, into a system than when the process is manual.
If you are wondering whether the automation of processing data contained in paper documents and iDoc is something that would help your business…