FME offers many functions and enables you to connect to any database and conduct various operation on it. Let us guide you on how to do bulk database updates!
Setting up an FME Database Connection
When you want to read to or write from a database – including database updates – you need authorization. FME defines authorization parameters using a connection tool. It’s accessed through Tools > FME Options in FME Workbench. So start Workbench, select Tools > FME Options and you will get this dialog:
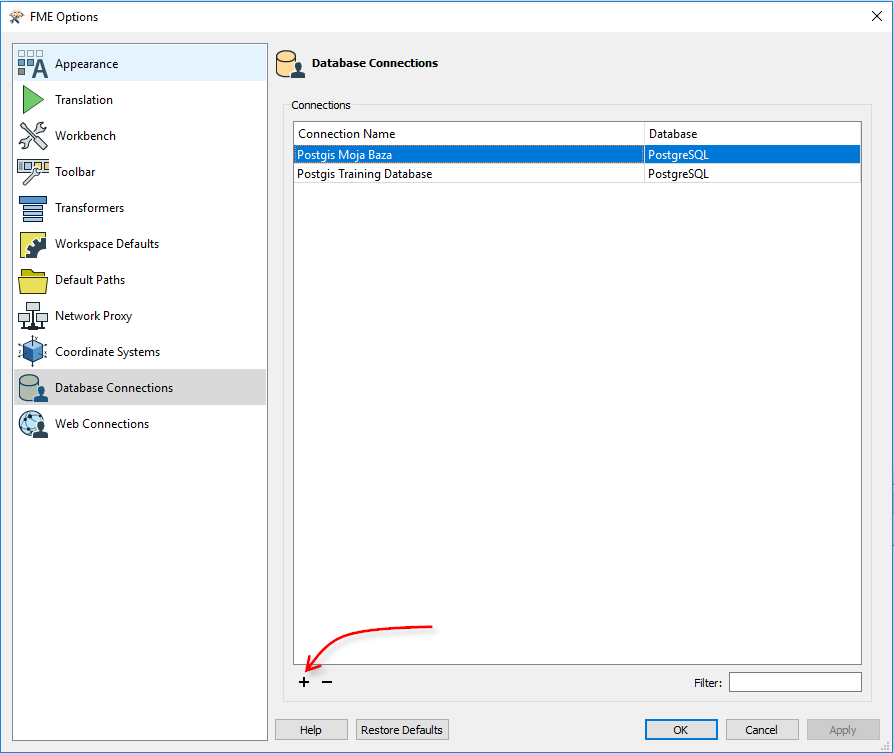
After clicking on Database Connections, you get a list of available connections. If you want to create a new one, press the plus button and you get this dialog:
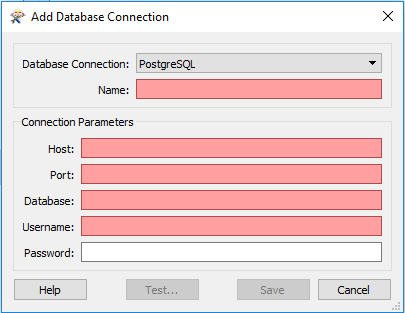
Enter your database details in there, test and then save. Now you have a connection defined, you can use it wherever you like in FME. So first let’s use it to insert some data into a database.
Inserting Data to a Database with FME
You don’t have any records in your database yet, so let’s start with loading some data in it. The generate option exists on the start page of FME Workbench, or you can use the shortcut Ctrl+G. That opens the basic dialog for defining a translation:
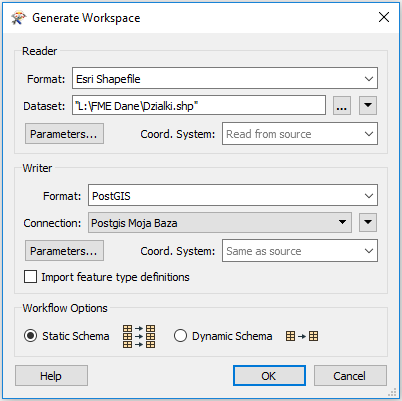
You have filled in the fields to define a translation of data about parcels in Krakow. The translation is from SHP file to PostGIS (a standard PostgreSQL database with a spatial extension). The spatial part is not necessary – the same setup works for data without a spatial component. The database connection you selected is the one defined earlier. Click OK and that dialog creates a workspace that looks like this:

Each object on the left is a table, layer or class in your source data. Each object on the right is a table in your database.
Setting Database Parameters
When using databases the key settings for each table are accessed by clicking the cogwheel icon on those objects, like this:
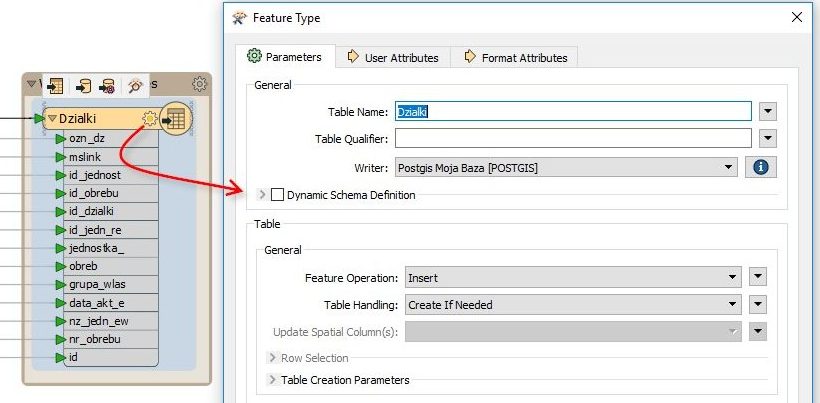
The table name is the first parameter, and so you can rename the table to be something different; and you can choose which schema (Table Qualifier) to write to as well.
But the most important parameter (Feature Operation) tells that you are INSERTing data, and you can also choose in what way the table is created:
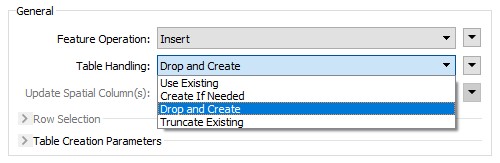
You can choose to create the table regardless of if it exists (Drop and Create), create it if it doesn’t already exist (Create if Needed), just add to the existing table (Use Existing), or empty it if it already exists (Truncate Existing).
Which you use depends on the scenario you’re working through, but in this case – to create and fill a table – use Create if Needed. The advantage over Drop and Create is that if another user already has a table with that name (and you haven’t checked) then at least you won’t delete their content first.
Run the workspace and FME loads the data:
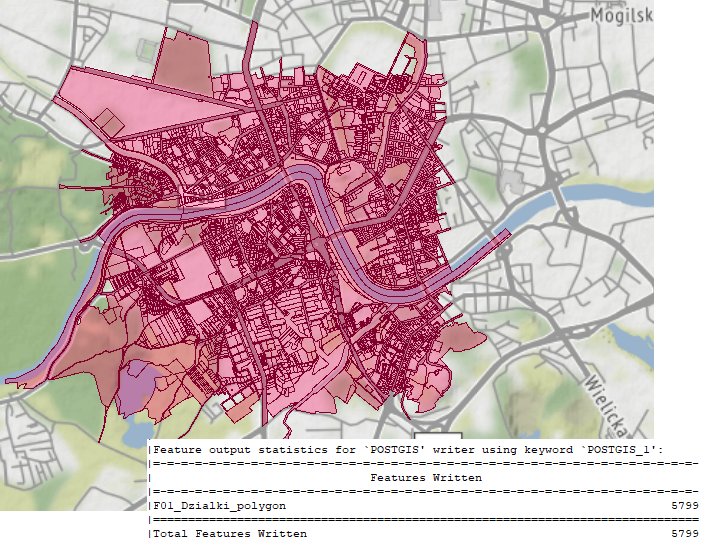 Of course, at some point in the future you might find the source of the data has changed, and need to update data based on that changed dataset.
Of course, at some point in the future you might find the source of the data has changed, and need to update data based on that changed dataset.
Updating Records in a Database with FME
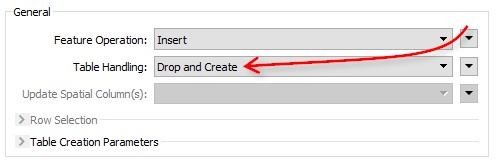
Let’s say you receive a dataset named Dzialki_update. The simplest way to update your database is to do the same process as above, but to use Drop and Create as the table operation. That way you’re just replacing everything:
But that relies on Dzialki_update being the full replacement dataset. What if it only includes the records that need an update? In that scenario you can simply change the operation to UPDATE (instead of INSERT) and choose to Use Existing table:
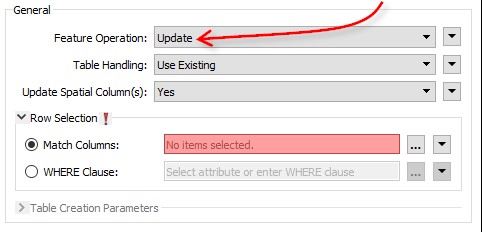
Notice that when you pick update, then another parameter becomes available to you: Match Columns. You need this to define which feature updates which record. In this case you have an attribute called ID_DZIALKI in your source data and a field (column) named ID_DZIALKI in your database table; so that’s the attribute you select:
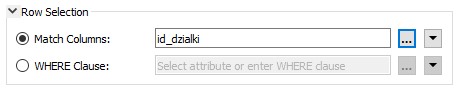
So if an incoming feature has the attribute ID_DZIALKI=12, then its contents are used to update the database record where ID_DZIALKI=12.
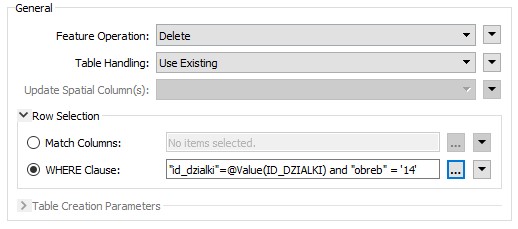
That’s simple enough, but to add a little complexity (not too much) there is also a WHERE clause you can use instead. This lets you define the match where the attribute and field names are not the same but also allows to add extra conditions using field names:

Here, for example, you’re updating records where ParkNumber = parkid, but also only where the neighborhoodname field is “14”. So records outside of this area aren’t updated, even if the park ID matches.
So you do updates here, and that’s simple enough – but what if you also want to delete records?
Deleting Records from a Database with FME
Let’s assume your Dzialki_deletions dataset is a list of records to delete from the database table, not add. To do that you simply change the operation from UPDATE to DELETE:
You get the same Match Column parameter (or WHERE clause) to define which incoming features should delete which existing records, and this is again easy to define. So deletes are no more complex than updates; the key question is what happens when you want to both delete and update records simultaneously?
Updating AND Deleting Database Records with FME
Let’s say some of the incoming records are updates, while others are deletions:
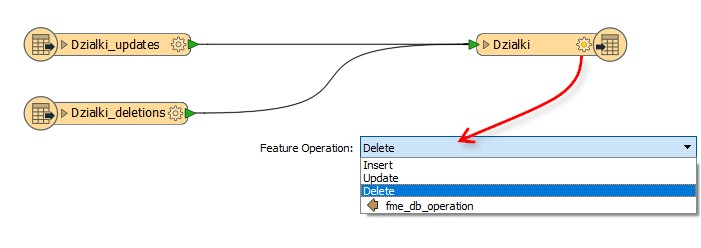
Obviously you can’t set the operation parameter to both DELETE and UPDATE for the entire table. What you do instead is tag each feature with the operation it will carry out. You do this using an attribute called fme_db_operation:
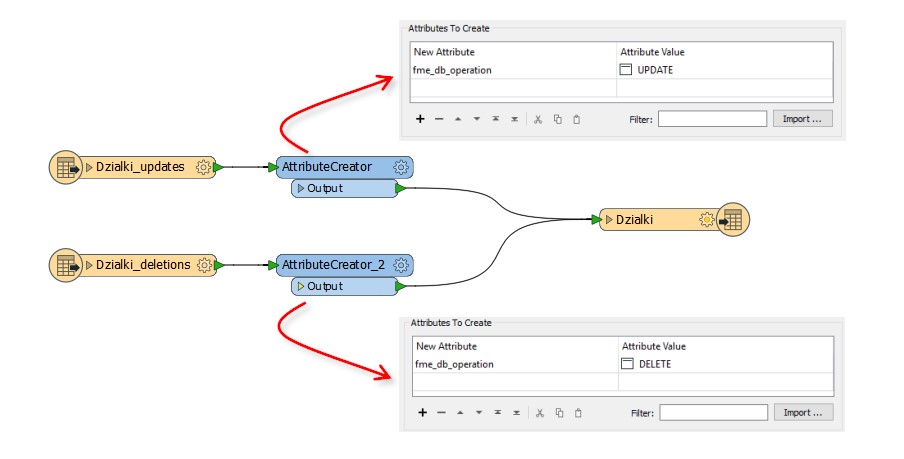
You can add an attribute to each stream of data, using an AttributeCreator transformer. The attribute name is fme_db_operation. For one lot of data set the value to UPDATE. The other set of data has a value of DELETE. This is how you tag each feature with its own operation.
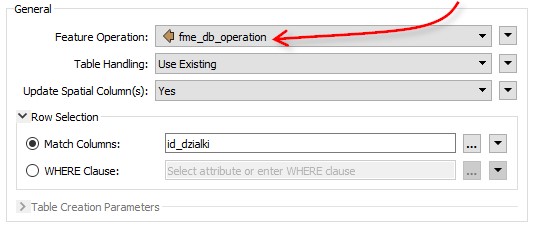
You still have to set the operation type on the table itself. But this time, rather than choosing Insert, Update, or Delete, choose the option labelled fme_db_operation:
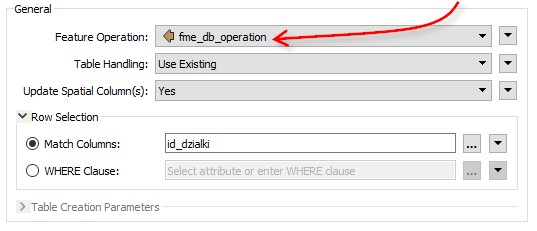
Now when you run the workspace, the features tagged UPDATE update database records, while the features tagged DELETE delete database records. The Match Column (or WHERE clause) provides a match between features and records.
The one assumption is that you already know which feature are deletes and which are updates. In the above example, the source data is already divided into two. If you’re not sure of that then you might need to do what is called Change Detection…
Change Detection and Database Updates with FME
Change Detection is where you have a new dataset and want to compare it to existing records to find what has changed. Here is such a workspace:
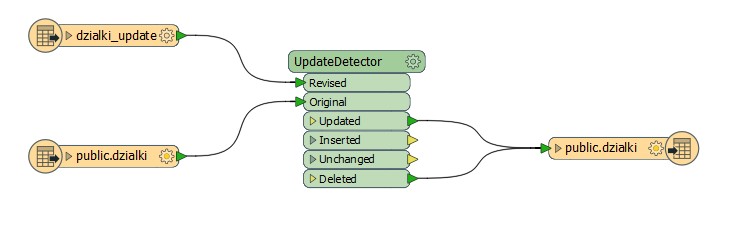
It looks quite simple, and in fact it is. You have added a reader (Readers > Add Reader) to read the existing contents of your database table, and an UpdateDetector transformer to compare these records to the public.dzialki dataset, to identify where changes have occurred. You can detect changes either on field values, or spatial contents, or both.
Then it’s just a case of writing the results back to the database table. You don’t even need to create the fme_db_operation attribute; the UpdateDetector has done that for you. You must just check that the table is set with the correct operation (fme_db_operation) and that Match Column is set.
What if each feature has a different match column? In that case you can write your match in the form of a where clause, and store it as an attribute. Then use that attribute for the match in the table parameters:

Summary
In this scenario we used PostgreSQL base, but most of the databases has identical interface in FME – working on a different file type shouldn’t be a problem. We hope the guide we prepared will be useful and our instructions will help you with database updates. Good luck!
Source: https://blog.safe.com/2018/10/beginners-database-updates-evangelist180/